What is Data Mesh ?
如標題所寫,這篇文章就是要跟大家解釋 Data Mesh 是什麼。其實我個人很討厭做這種 Buzzword 的內容,Date Lake, Lake House, Data Warehouse,每年都會蹦出幾個新花樣,其實只是想要框你錢買下他們的產品。
但身為一個學者,我認為這些 Buzzword 的背後,一定有一些值得學習的特點是可以做出一個真的產品的,而且是大家需要,真的能改善大家日常工作流程的那種。
順帶一題,我會把我腦子想的也跟你們分享,首先我要知道哪個網站是可以相信的,如下圖所比較
如何判讀資訊
 這種網站就是大便,因為網站建立者的意圖就是要你去點它旁邊的廣告,可想而知提供的資訊八成也是大便。(我怕毀損別人商譽,我沒有特訂針對只是個人看法而已)
這種網站就是大便,因為網站建立者的意圖就是要你去點它旁邊的廣告,可想而知提供的資訊八成也是大便。(我怕毀損別人商譽,我沒有特訂針對只是個人看法而已)

 下面這兩個網站就是我覺得可以相信的網站,一個是我以前量子物理的老師的網頁筆記,另外一個是 MIT 6.5840: Distributed Systems 這門我自己很喜歡的課程,看出差別了嗎,這種雖然排版配色都沒有下上面那個網站多工夫,但是你會馬上知道這!個!網!站!是!寶!
下面這兩個網站就是我覺得可以相信的網站,一個是我以前量子物理的老師的網頁筆記,另外一個是 MIT 6.5840: Distributed Systems 這門我自己很喜歡的課程,看出差別了嗎,這種雖然排版配色都沒有下上面那個網站多工夫,但是你會馬上知道這!個!網!站!是!寶!
這個網站除了告訴你事實,它就沒有其他屁用。
原汁原味的 Data Mesh
好啦!話題回歸那樣 Data Mesh 要怎麼開始研究呢?
我直接開始讀 Data Mesh 這個詞發明人 Zhamak 的文章,而且網站是不是也是個值得 “信賴” 的呢?(看看我上面風格的說明)

就她的觀察,大家比較會採用的架構就是 ETL 拉到分析的團隊和他們的基礎設施上。

阿然後你也知道,公司規模一變大就會變成這種亂七八糟的模式。
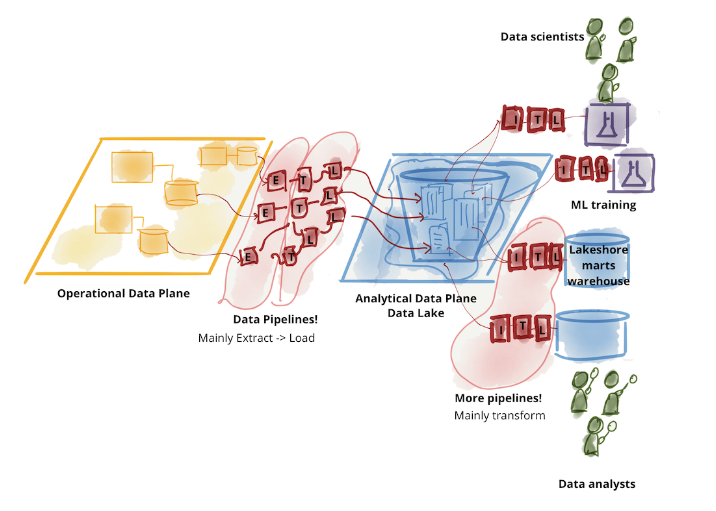
所以 Zhamak 就發現這其實是團隊結構性問題。
改成像是下面這樣,每一個 Operational Team 再提供一組 API,給內部使用,我需要用到什麼資料,我可以像是吃自助餐 Buffet,隨時選我想要的資料來使用。
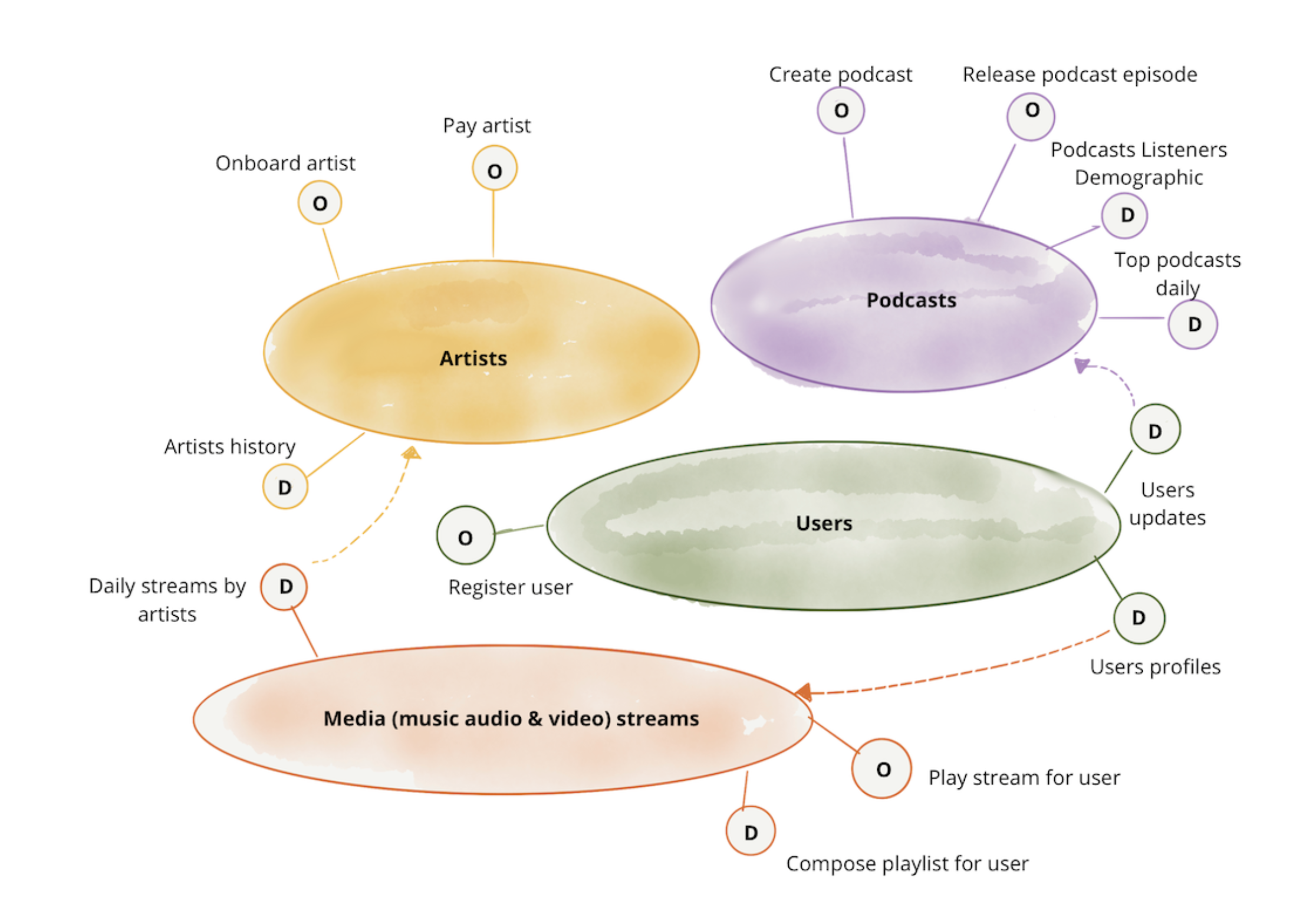
美景有了,現在就剩下實作的問題,原作者也給了下圖一樣的建議,我們一一仔細說明其內容!

實作方式
那上圖那些 API 要怎麼實作呢?
作者給出的建議是要滿足三個條件:
- 有自己的基礎設施 (像是 運算資源 和 儲存空間)
- 有自己邏輯該執行的 Code
- 提供多種的資料格式
Kubernetes
那我們就一個一個來解決吧,有自己的基礎設施最簡單的方式就是設計成 Kubernetes 的 StatefulSet 這項想要製作新的 Data Product 直接新增 YAML 就可以了。
NATS/JetStream
接著就是我最頭疼的問題,Data 要保存在哪裡,我第一個想到的就是 NATS 這個是連台積電都再用的 CNCF 專案喔 (我甚至去聽過他們的演講)。
NATS 以前只是一個 Message Broker,直到 v2.0 之後開始做得跟 kafka 一樣的有 Exactly-Once、Pull-based…。而且最重要的 NATS Image 只有 15MB 阿!
Embedded Database Engines
好了,我現在手上有 Stream 可以用了,我只要寫一些 Code,就可以把 Stream 儲存的格式,直接轉化成各式各樣的類別,舉例來說:Dgraph 有開源一個 Go 的 Embedded Key-Value Engine,這個可以拿來當 rocksdb 用,而且 New York Times 的工程師還公開在演討會上分享自己怎麼用這個 Key-Value Engine 來開發。
OLTP 的部分已經搞定了,解下來就是 OLAP,簡單科普一下,現代的 OLAP Engine 通常都不做 Storage 了,要分析的時候直接從像是 S3 的 Object Store 拉出來就好,像是 Trino、Velox、DuckDB。
因緣際會下,我在 Youtube 有聽了幾場 DuckDB 的演講,作者想要把 OLAP 的 SQLite 做出來,所以我也 Embed 進去我的設計裡面。
Data Product 的部分我想已經設計完成了,接著就是這些 Data Product 怎麼被管理,恰好 NATS 有 Leafnode 的功能,我直接拿來用,現成的 Hub-Leaf 網路架構幫我省了不少麻煩。
在兩個星期的努力後,我終於設計出了一個 MVP,想體驗看看可以直接 Quickstart 體驗我設計的系統一下。